Overview
Mirror WebScrapper is a distributed, three-tier architecture. Instead of manually writing scrapers for every new website, this system uses a multimodal AI (Vision + Text) to analyze a page and automatically generate the extraction logic.
Virtual Machine (VM-A) that serves as a target environment. The main app (webscrapper) running on Server (VM-B). The Server-AI, running a custom Python intermediary script that facilitates communication between the App Server (VM-B) and LM-Studio (Server-AI). The code generation and text extraction happens here.
Project Demo
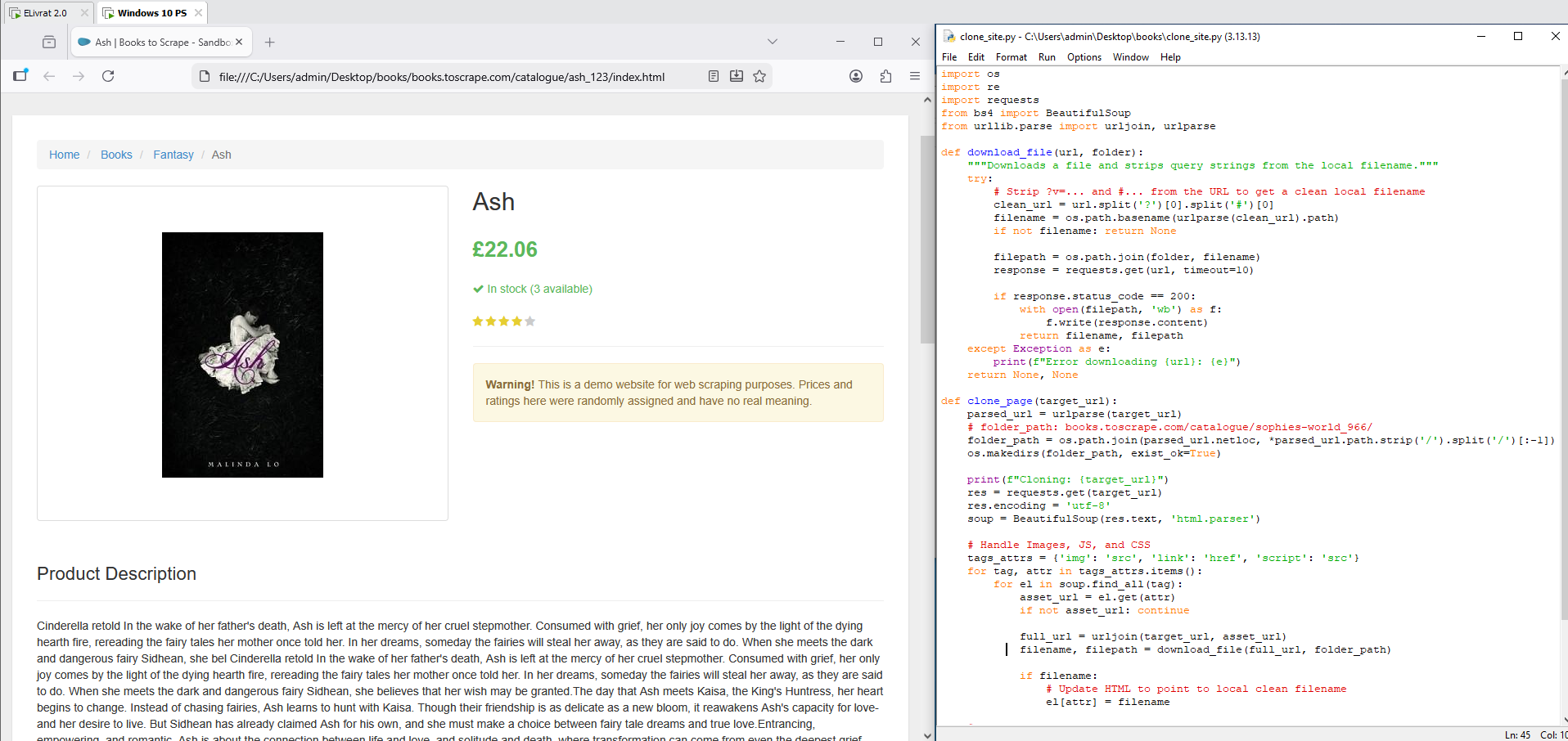
Step 1 — Creating a High-Fidelity Web Server Mirror
To build a "Scraper Sandbox" on a dedicated Virtual Machine (VM-A) that serves as a target environment. This ensures that the web-scraping and AI-analysis logic can be developed and tested without violating terms of service, hitting rate limits, or being affected by network instability.
Mirroring a modern website is not as simple as saving HTML. Modern sites rely on complex relative paths, asset dependencies, and font-icons. The main challenges addressed here were:
- Asset Linkage: Automatically identifying and downloading CSS, JavaScript, and Images.
- Encoding Conflicts: Solving the "£" issue by forcing UTF-8 decoding and serving custom HTTP headers.
- Font Rendering: Solving the "Yellow Square" problem by stripping URL query parameters (like
?v=3.2.1) from CSS files to match local file system naming conventions. - Hierarchical Routing: Building a dynamic
index.htmldashboard that scans the directory structure to provide a clickable interface for all cloned resources.
Tech Stack Used:
- Python (Requests & BeautifulSoup): To programmatically clone pages and patch internal code.
- Regular Expressions (Regex): To surgically remove version strings from CSS files.
- HTTP Server (Python socketserver): To host the mirror and serve custom UTF-8 headers.
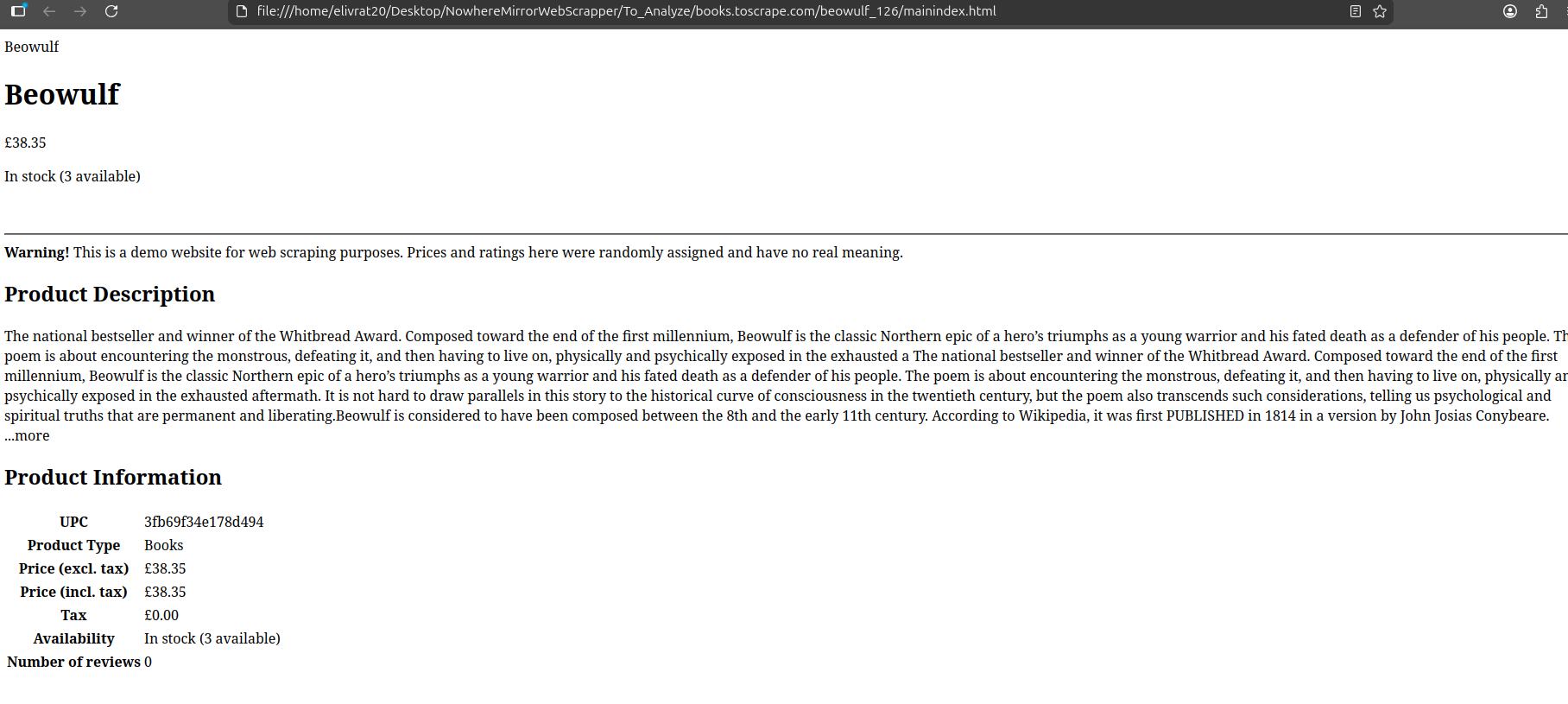
By the end of this step, a mirror from the original site (books.toscrape.com) was successfully created in a browser. This includes:
- Asset Integrity: Full CSS and Font-Awesome support for accurate & clean URLs — no messy browser-saved folders; just a logical
/catalogue/product/structure. - Portability: The entire mirror can be moved to any VM and hosted instantly using a single Python script.
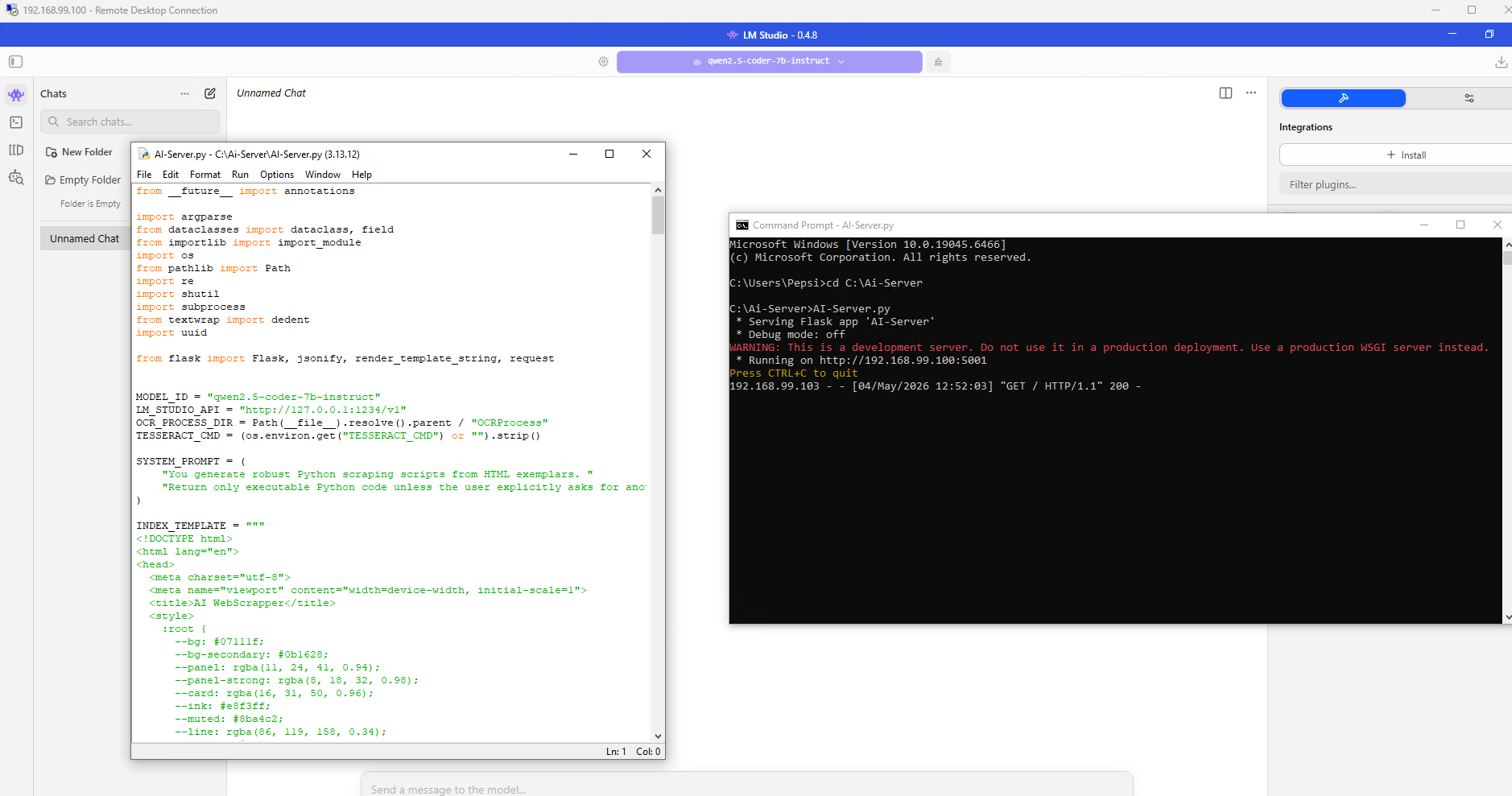
Step 2 — The AI Bridge Script
A custom Python intermediary script facilitates communication between the App Server (VM-B) and LM-Studio (Server-AI). This bridge handles API requests and injects specialized system prompts and multi-shot instructions to maximize the accuracy of the AI-generated scraping functions.
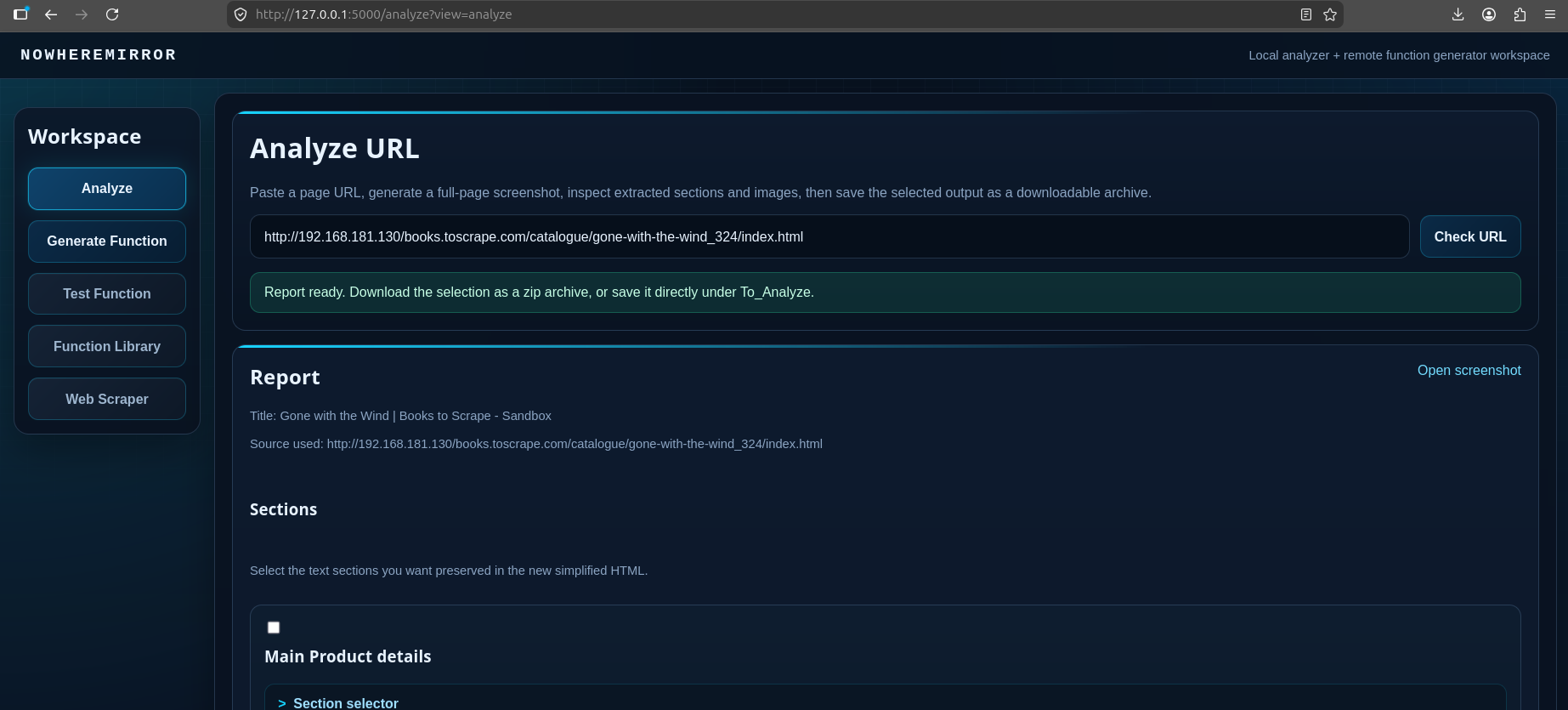
Step 3 — Main Application Workflow
DOM Sanitization & UI Selection
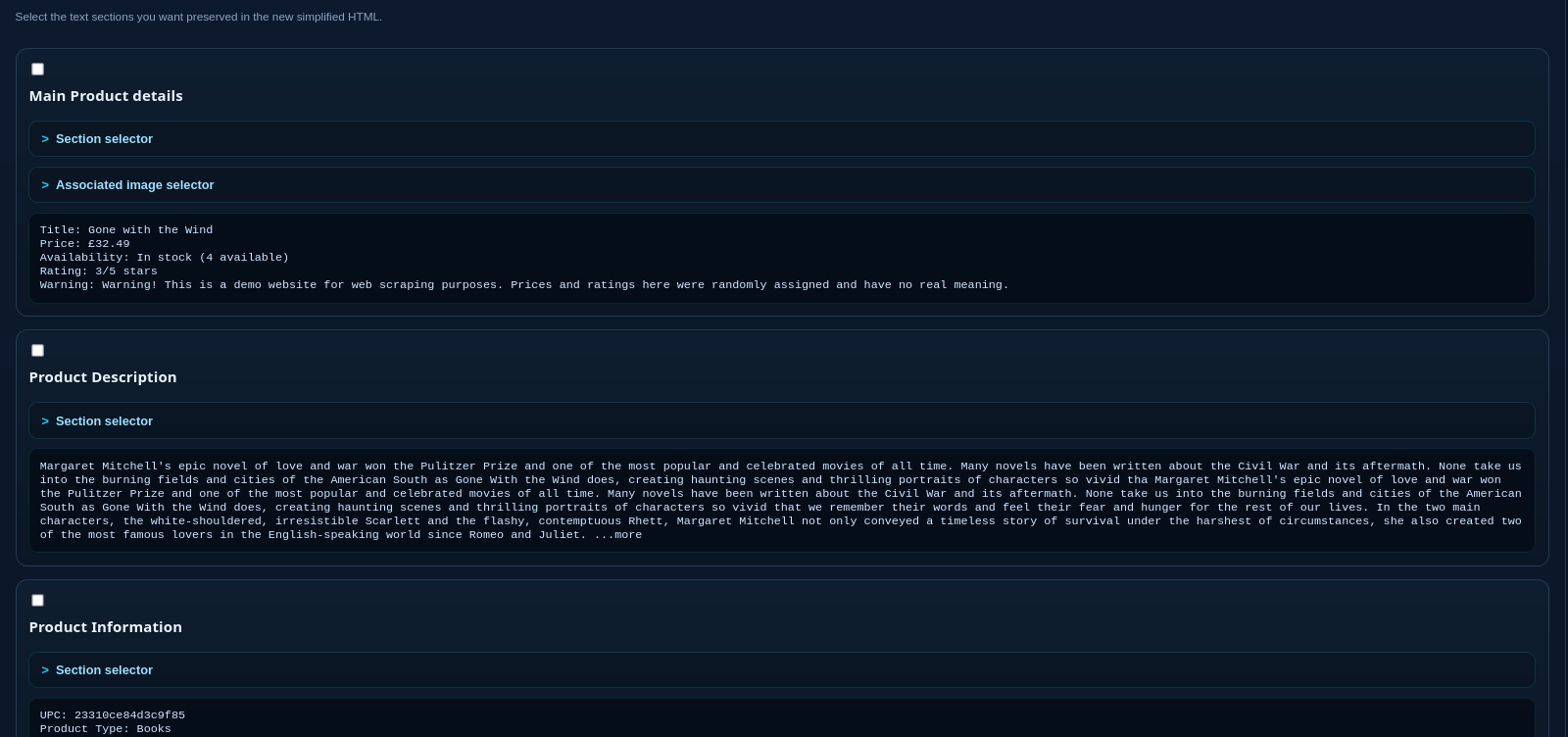
The system ingests a target URL and generates a "Naked HTML" version. By stripping scripts, styles, and fonts, the app presents a clean structural view. The user interacts with this simplified layout to select specific data points (e.g., Price, Title) they wish to extract.
Selecting Specific Data Points
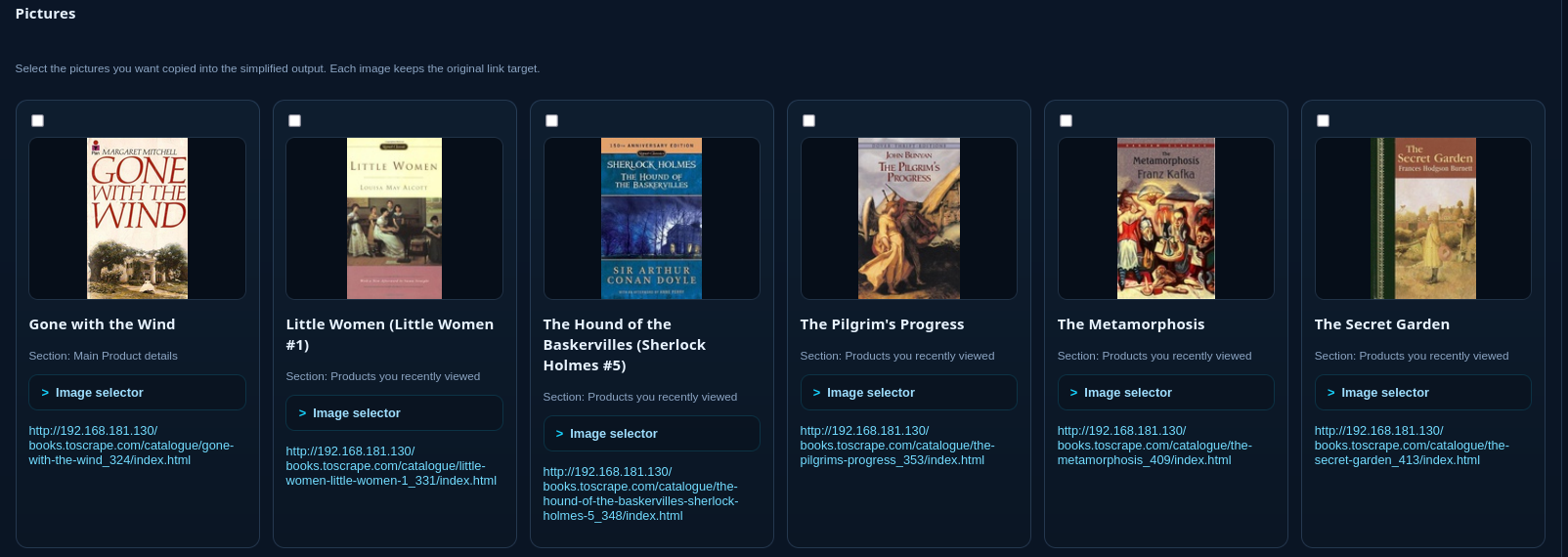
Multimodal Payload Transmission
The sanitized HTML and the page screenshot (to be used later) are bundled and transmitted to the Server-AI. The Bridge Script formats this data for the LLM. The app then provides a live preview of the generated Python tool, allowing the user to perform "Human-in-the-Loop" (HITL) refinements through natural language chat or manual code edits.
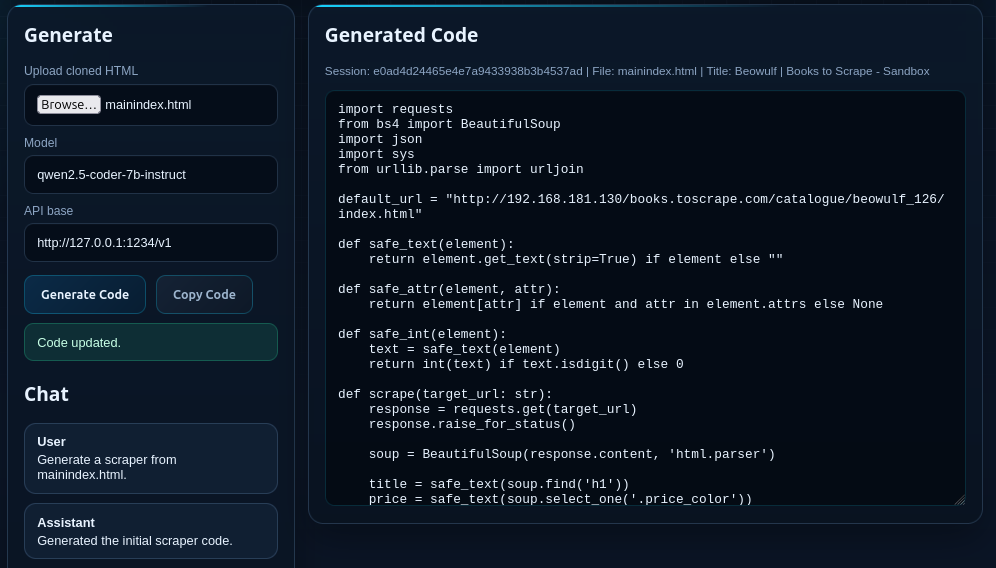
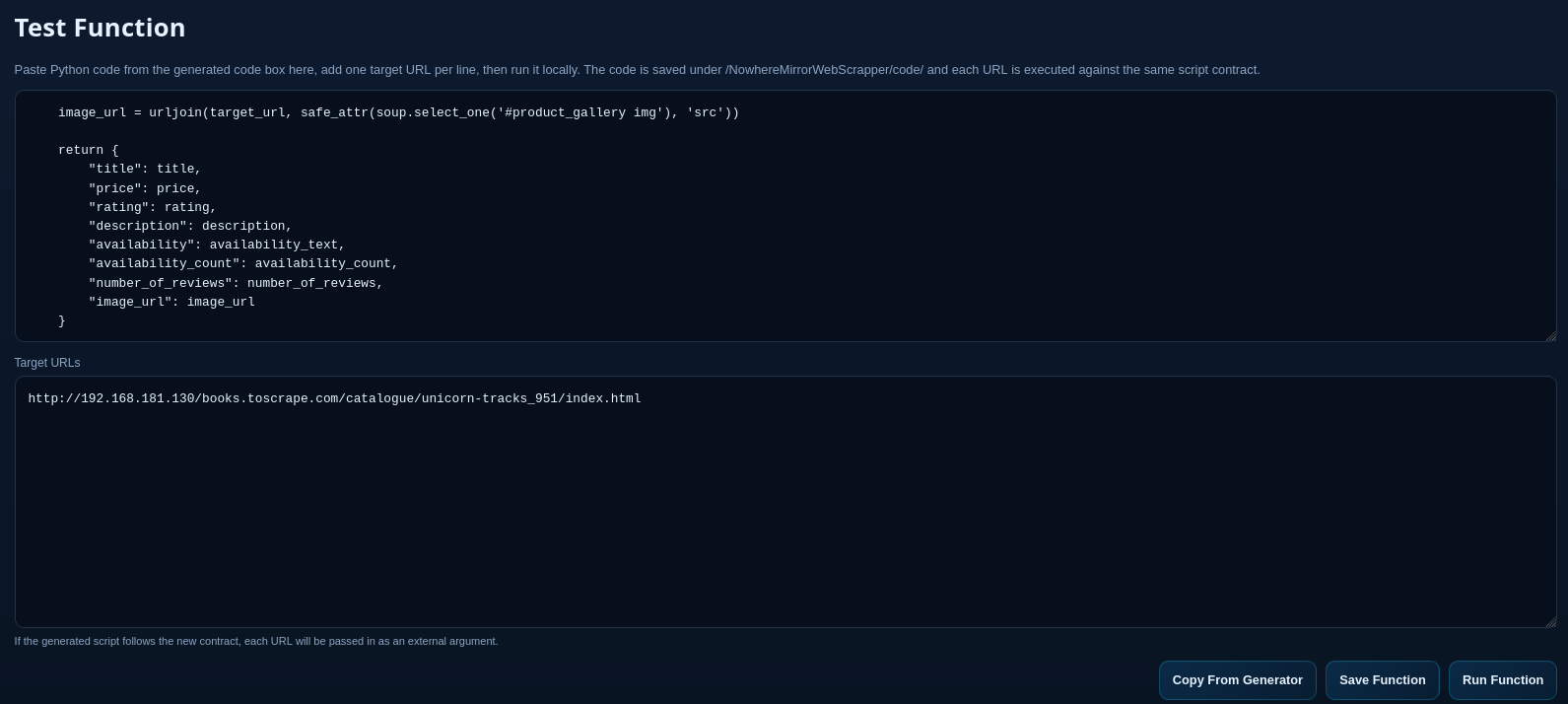
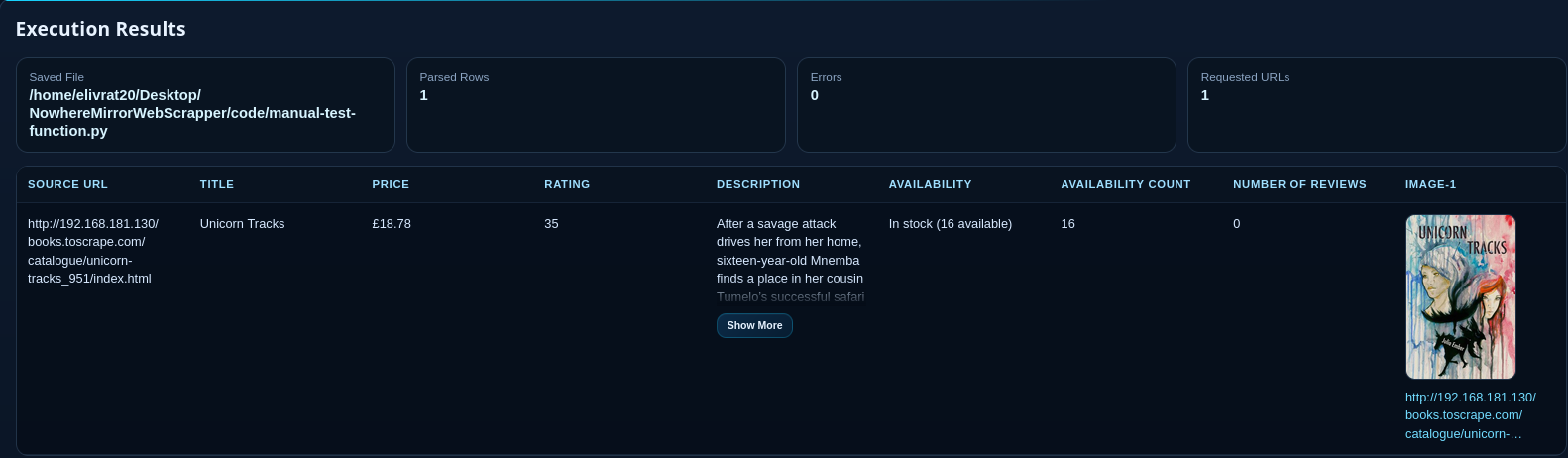
Validation & Sandbox Testing
Users can execute the generated function within a built-in sandbox to verify the output. Once the data extraction meets the required accuracy, the function is committed to the local library.
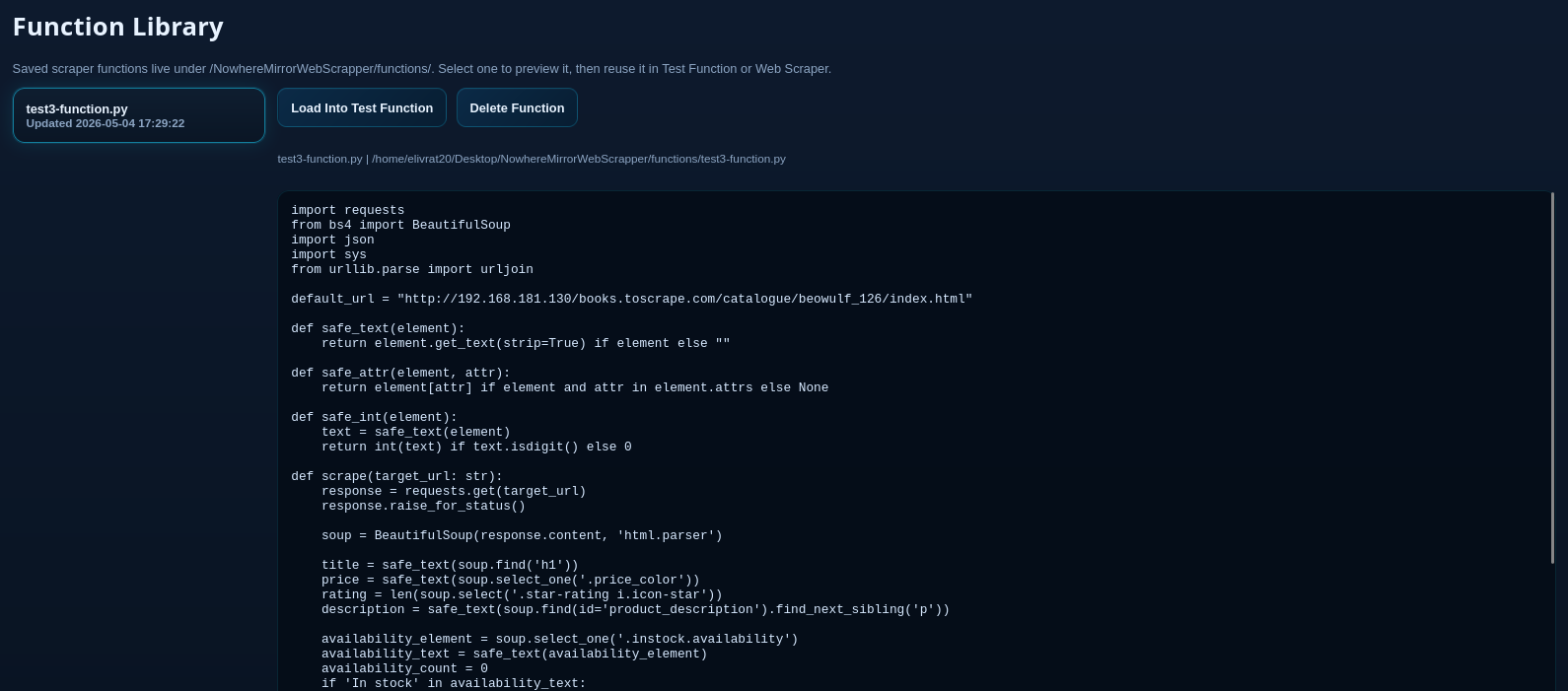
Function Library
A centralized repository where users manage, version-control, and retrieve previously generated scraping scripts.
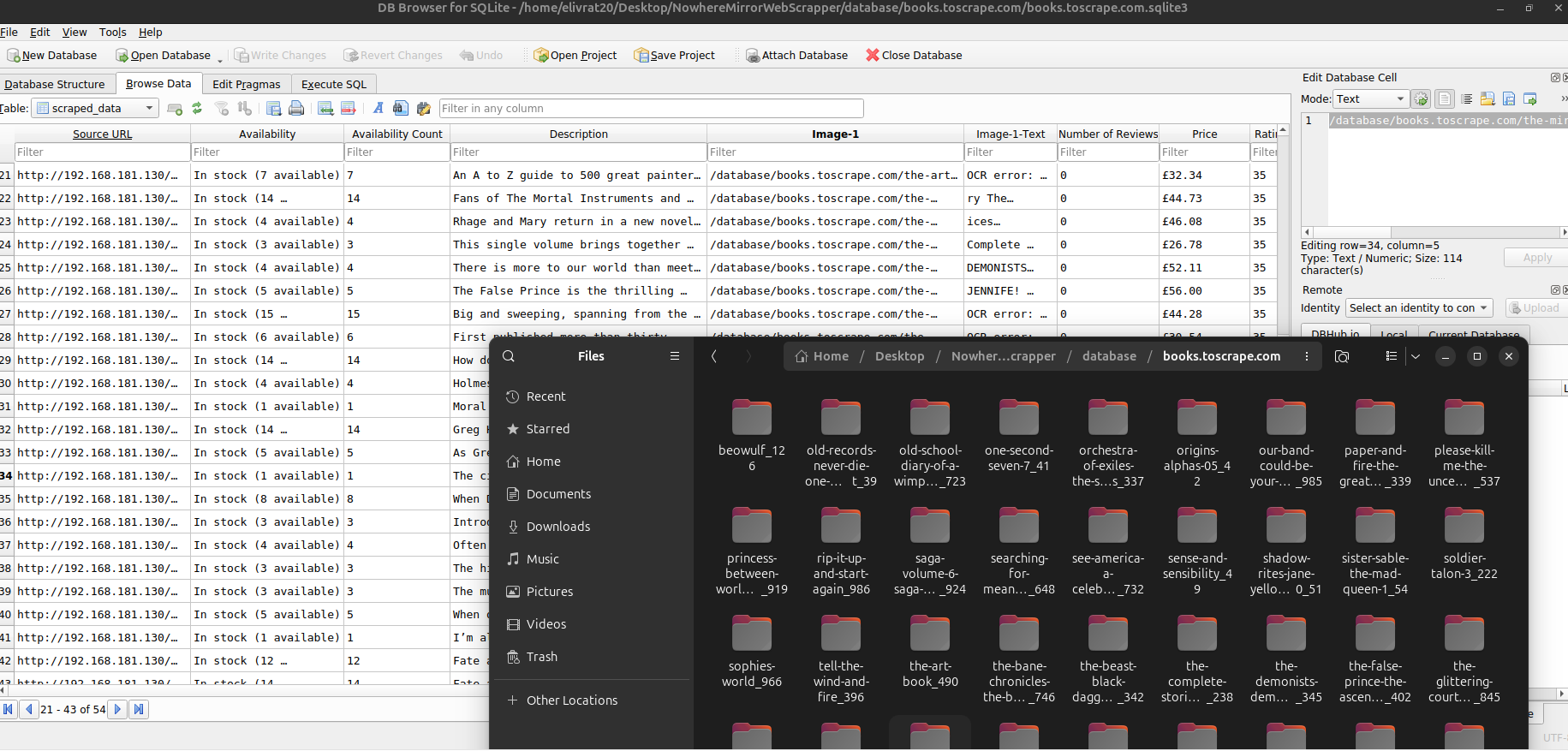
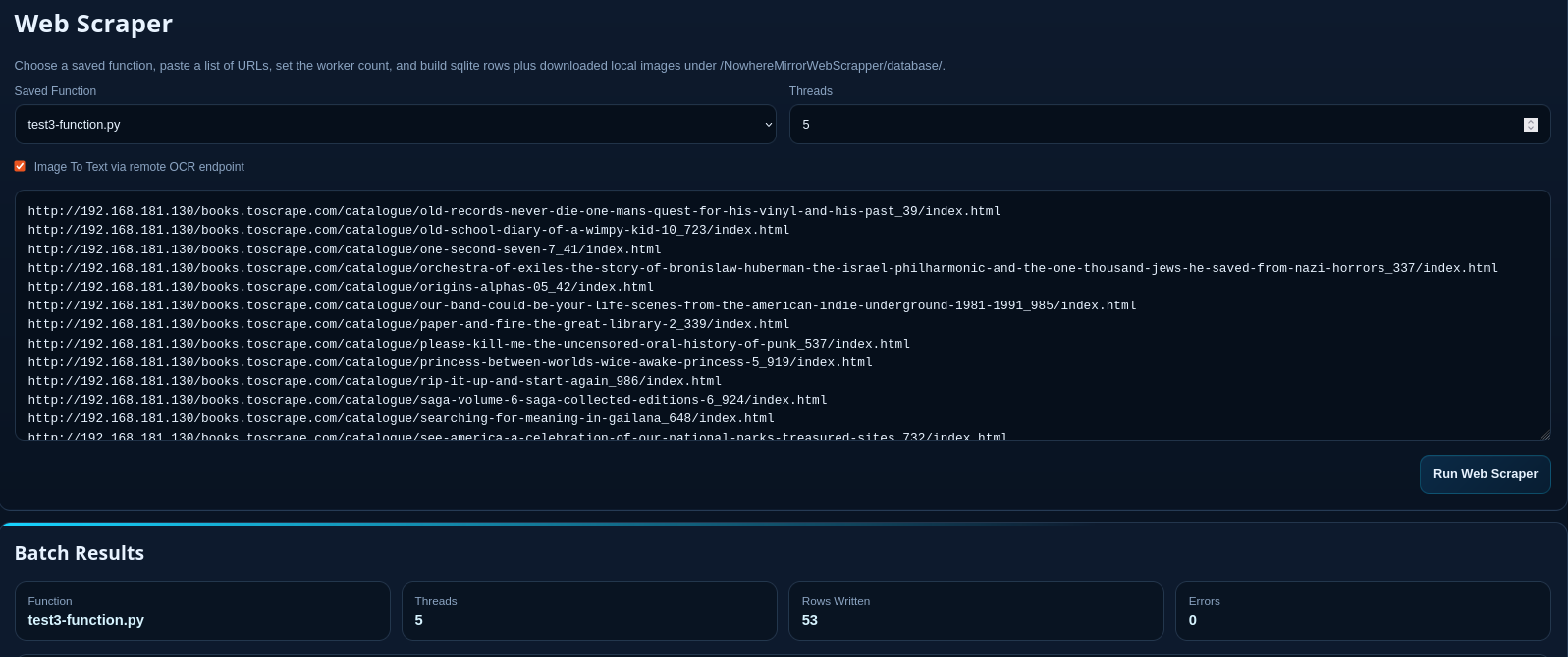
Distributed Web-Scraper
The final execution engine. Users can:
- Input a list of URLs or a domain-wide crawl request.
- Configure multi-threading for high-speed extraction.
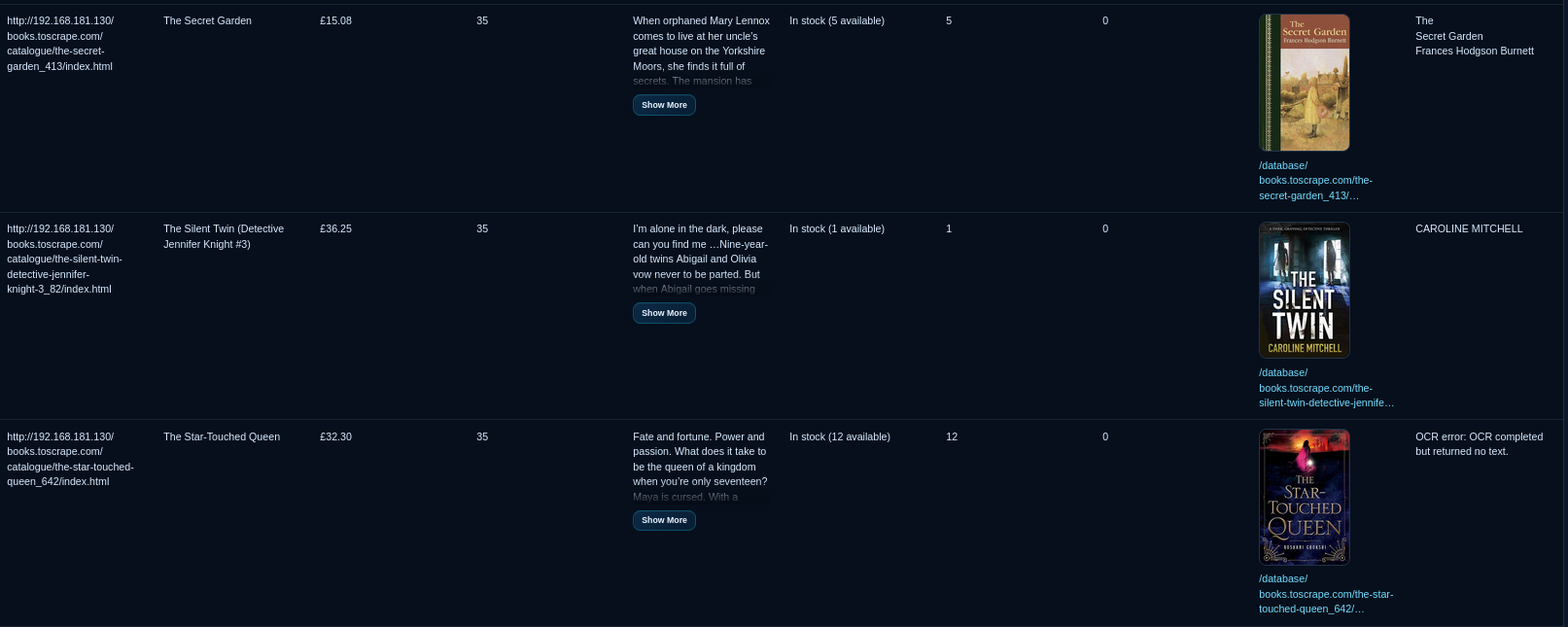
- Enable AI-Vision OCR to extract text data from product images.
Output: The system auto-generates a domain-specific directory containing a SQLite3 database and organized image folders.
System Architecture
Server-AI (The Logic Tier)
The 1080 Ti-powered server hosts three distinct API endpoints via the Bridge Script:
- Synthesis Engine: Generates Python extraction code.
- Dialogue Controller: Handles iterative refinements between user and AI.
- Vision/OCR Engine: Extracts text from image assets using local processing.
- Job Management: To prevent VRAM overflow, the server implements a Job Queue. Requests are processed sequentially (1-by-1) for the LLM, while OCR tasks utilize multiprocessing to maximize hardware utilization.
App-Server (The Orchestration Tier — VM-B)
VM-B manages the global state and workflow orchestration. To prevent hardware bottlenecks, the architecture uses Asynchronous Task Offloading:
- Phase 1 (Network Intensive): The scraping threads execute the generated Python functions to grab HTML and image files.
- Phase 2 (Compute Intensive): Image data is offloaded to Server-AI for OCR processing.
Non-Blocking Logic: The main application does not wait for OCR completion; instead, it streams images to a temporary buffer on Server-AI. As the AI completes each image, the data is pushed back to the database on VM-B, and the temporary file is purged to maintain a lean footprint.
Database Creation